












刚开始学C语言的时候,都感觉它除了在命令行里打印点东西之外,没有其他用处。
但是,又不断地听说Linux系统是C语言写的。
总之,就是感觉C语言名不符实,心理落差太大。
那么,咱就说说C语言是怎么写操作系统的。
C语言几乎是写操作系统的唯一语言,就是因为它可以手动管理内存,而又不像汇编的可读性那么差。
1.C语言的全局内存模型最简单。
C语言有指针,可以通过指针对内存进行细致的管理。
同时,C语言不依赖运行时的状态,对内存管理模型的要求很简单:所有的全局数据都是被常量初始化的,在main()函数运行前不需要初始化代码。
上面的代码里,g_a是个全局变量,它的初始化要在main()函数运行之前:可以在编译阶段初始化,也可以在main()函数前先运行一段初始化代码。
C语言对g_a的初始化,就是在编译阶段。
编译器在生成.o文件的数据段时,会直接把g_a对应的数据初始化成1。
全局数组、全局结构体的初始化,也是用“常量初始化”的:
这点虽然不那么直观,但它确实是常量初始化的。
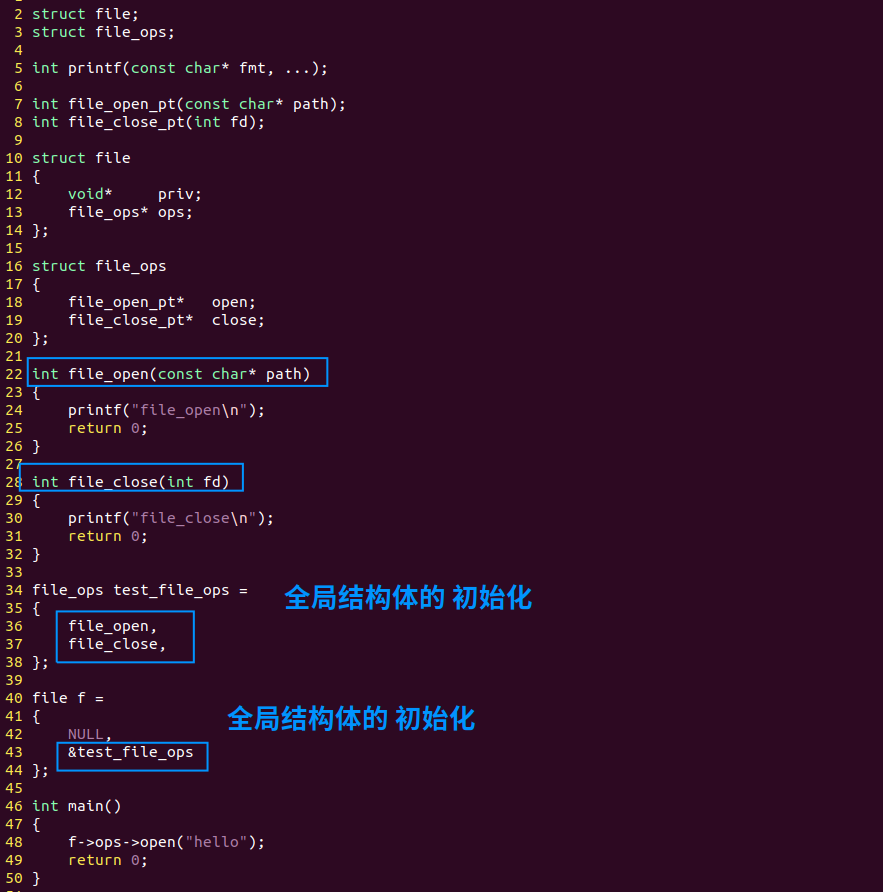
如上图,test_file_ops结构体里虽然填的是函数的地址,看上去像个变量,但实际上:
- 编译器在生成.o文件时,是知道哪个函数放在文件的哪个字节的。
- 连接器在生成可执行文件时,不但知道哪个函数放在哪个字节,还知道它会被加载到哪个内存地址。
所以,这种结构体里看上去是“变量”的内存地址,实际上也是常量。
C程序员不需要关注具体的数值,但编译器会把它计算出来的。
所以,C语言的内存模型,都是在main()函数之前的编译阶段就可以确定的。
操作系统在运行程序时,只需要把文件加载到内存里,然后跳转到main函数就行了不需要管运行时的状态。
但是,C++是不可以这样的。
2.C++的全局内存模型,依赖运行时状态。
C++要是给你写个动态创建机制,那么在main()函数运行之前,就要运行初始化代码,至少要把CRuntimeClass的类图构建出来才行:否则去哪里查找类名对应的构造函数呢?
C++动态创建的演示代码,如这3张图:
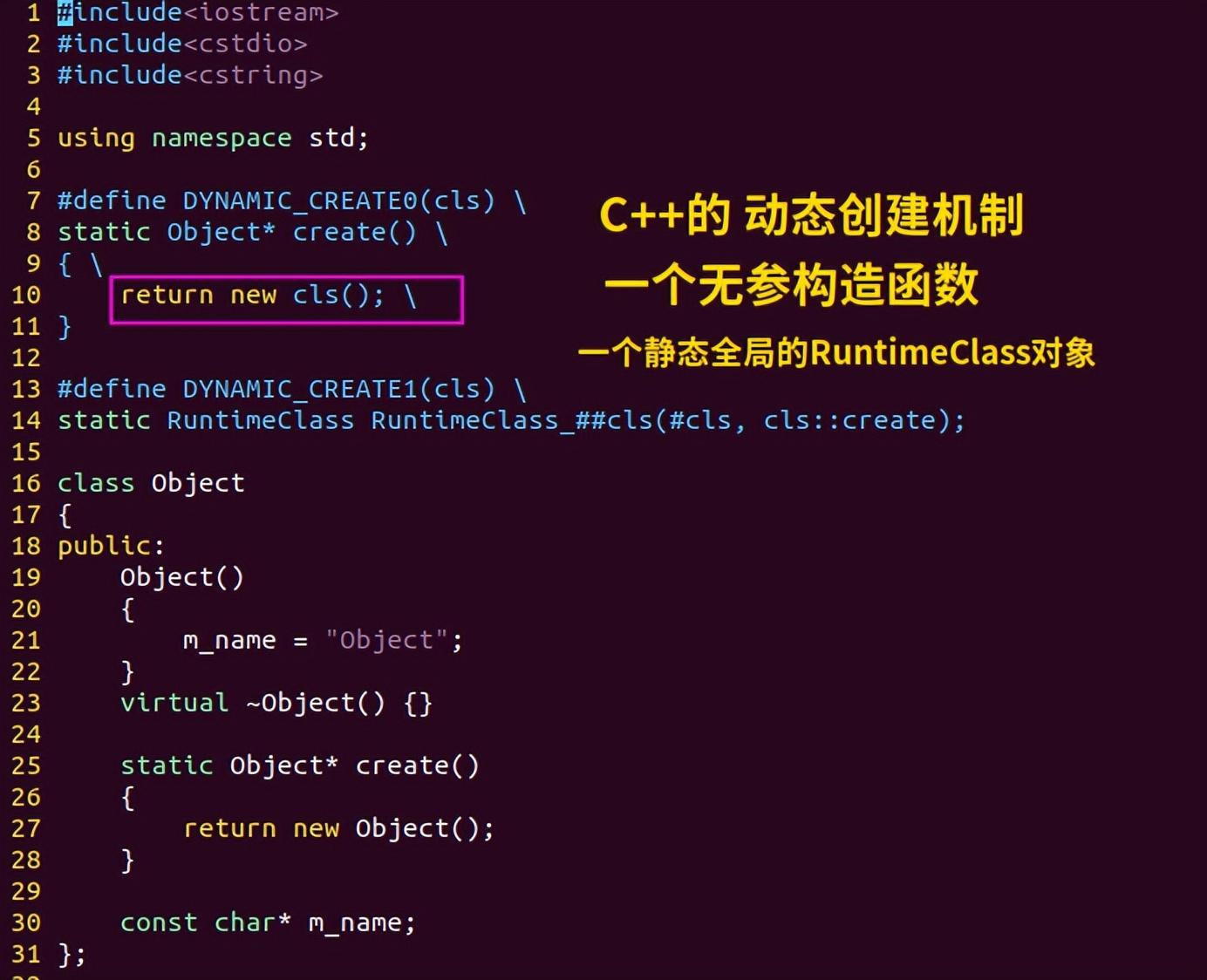
动态创建代码,1
所谓的动态创建,是在收到类名字符串之后,创建一个对应的类对象。
当然没法用new "Object"去创建Object类的对象,因为"Object"是字符串常量,不是编译之前的代码。
所以C++就需要一个静态函数,这个静态函数里只有1条代码:return new Object();
因为每个可以动态创建的类,都需要这么一段代码,所以把它写成了上图的静态函数,并且通过一个宏把它添加成每个类的静态成员函数。
但是,在收到类名字符串之后要找到这个函数,必须得有类图。
每个OOP语言都有个庞大的RuntimeClass类图,就是做这个事的
类图,就是由每个类的RuntimeClass全局静态对象构成的链表。
在每个类里添加一个RuntimeClass的静态对象,它的构造函数在运行时就会把它自动挂到类图的链表上,如下图的红框所示。
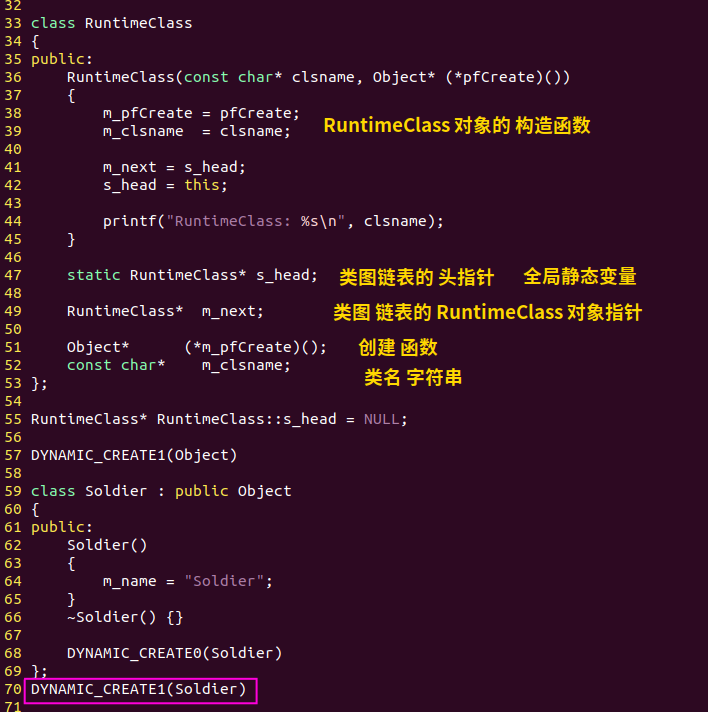
动态创建代码,2
这个RuntimeClass对象,既然是全局静态对象,那么它的构造函数当然要在main()函数之前被调用!
那么C++的编译器框架,怎么保证这点呢?
只能在main()函数之前给可执行文件添加一个.init段,让程序的入口在.init段里,而不是main函数所在的.text段。
但是在Linux系统里,是绝对不允许编译器在程序员之前、对内存做手脚的!
这就是Linux之父吐槽C++的原因:因为他感觉自己的能力受到了质疑,感觉C++编译器认为他管不好内存
但是,C编译器绝不会这么认为,C语言认为每个程序员都是大牛,都该自己管内存
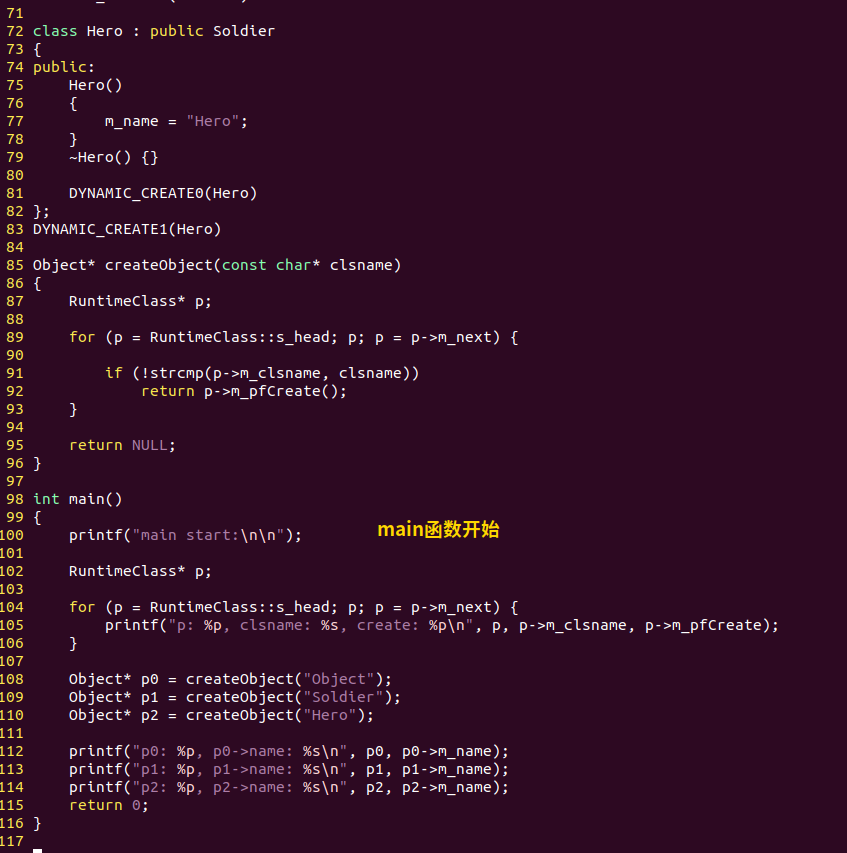
动态创建代码,3
这个代码的运行效果:
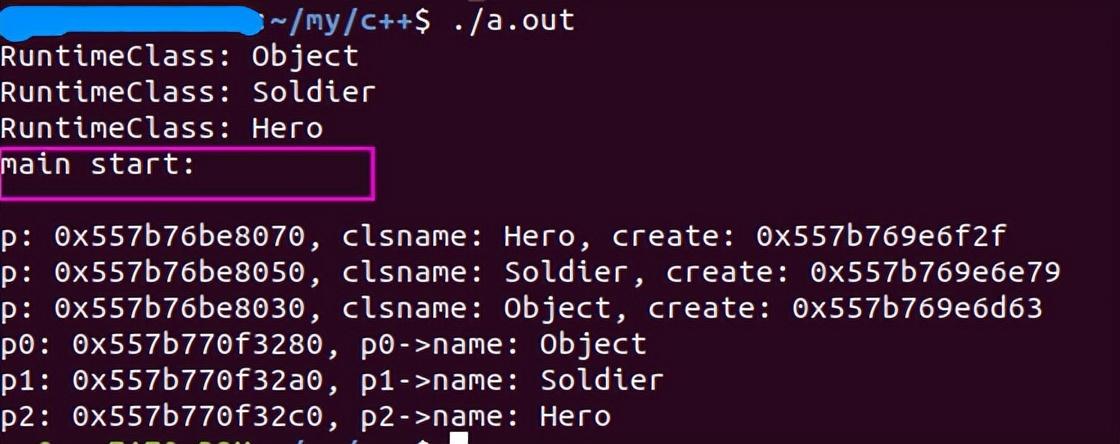
效果图
可以看到,那3个RuntimeClass的初始化都在main start之前,因为它们是全局静态对象。
所以,C++见到的程序入口,并不是真正的入口,在main()之前就要进行内存初始化的。
但是,C的入口是真正的入口:你想让它做什么,它就做什么,只要你把代码写对了。
每个敢写操作系统的C程序员,恐怕都认为自己能把代码写对。
所以,C语言几乎是系统程序员的唯一推荐语言。
3.怎么写操作系统?
咱先论证完了C语言写操作系统的存在性和唯一性,然后再给它个构造性的证明。
操作系统,是最贴近硬件的软件。
它和编译器是互为递归的关系:编译器在操作系统上运行,操作系统是编程语言写的,编程语言是编译器编译的。
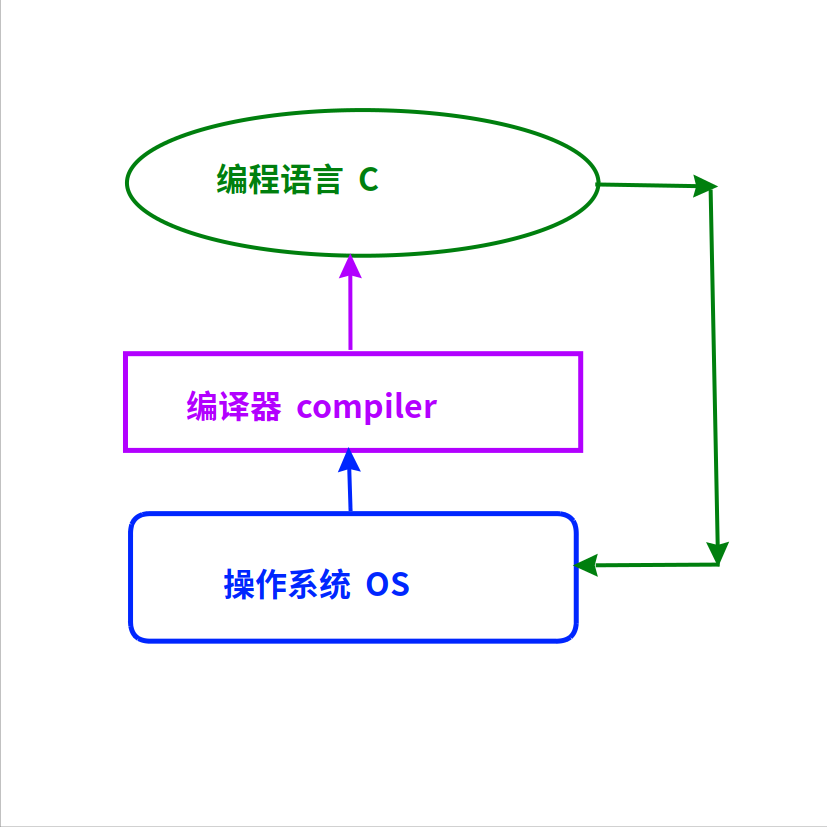
操作系统、编译器、编程语言的关系
操作系统大约分为这4个模块:进程管理、内存管理、设备管理、网络子系统。
进程管理、内存管理,这2个是操作系统的核心模块。
操作系统要想运行起来,进程和内存的管理是必需的,其他模块可以后来一个个的添加。
内存管理模式,是操作系统可以运行的关键:主要是分段和分页两种。
4.内存的分段
内存的分段,就是把内存分为代码段、数据段、堆栈段,给予不同的权限进行管理。
代码段,具有可读(R)、可执行权限(X)。
数据段、堆栈段,具有可读(R)、可写权限(W)。
数据段和堆栈段的差别是:数据段从低往高增长,堆栈段从高往低增长。
它们两个之间的没使用的区域,是堆和栈可以增长的空间。
通常所说的堆栈段实际上指的是栈,堆是紧邻着数据段的。
代码段的内存地址,要放在段寄存器CS里。
数据段的内存地址,要放在段寄存器DS里。
堆栈段的内存地址,要放在段寄存器SS里。
这3个寄存器,在用户代码里是不可以使用的,但内核代码可以。
在内核初始化时,给哪个段寄存器加载哪个内存地址,它就会把哪个地址当成哪个段。
这个机制,是由intel的CPU设计所保证的。
在16位机上,是只能用分段模式的,即所谓的实模式。
段地址+偏移量的访问方式,最大访问1M的内存,是实模式的唯一方式:
CS:IP是代码的运行位置,
SS:SP是栈的位置,
DS:SI和ES:DI用于数据传递的源位置和目标位置。
32位机之后,intel又增加了保护模式:保护模式在分段的基础上可以分页,也可以只分段。
5.内存的分页
CPU进入保护模式之后,才可以开启分页机制。
页的大小一般是4096字节(2^12),所以页基地址的0-11位是0。
这些为0的12位,在页表里用于每个页的权限控制:读、写、执行、缺页,etc.
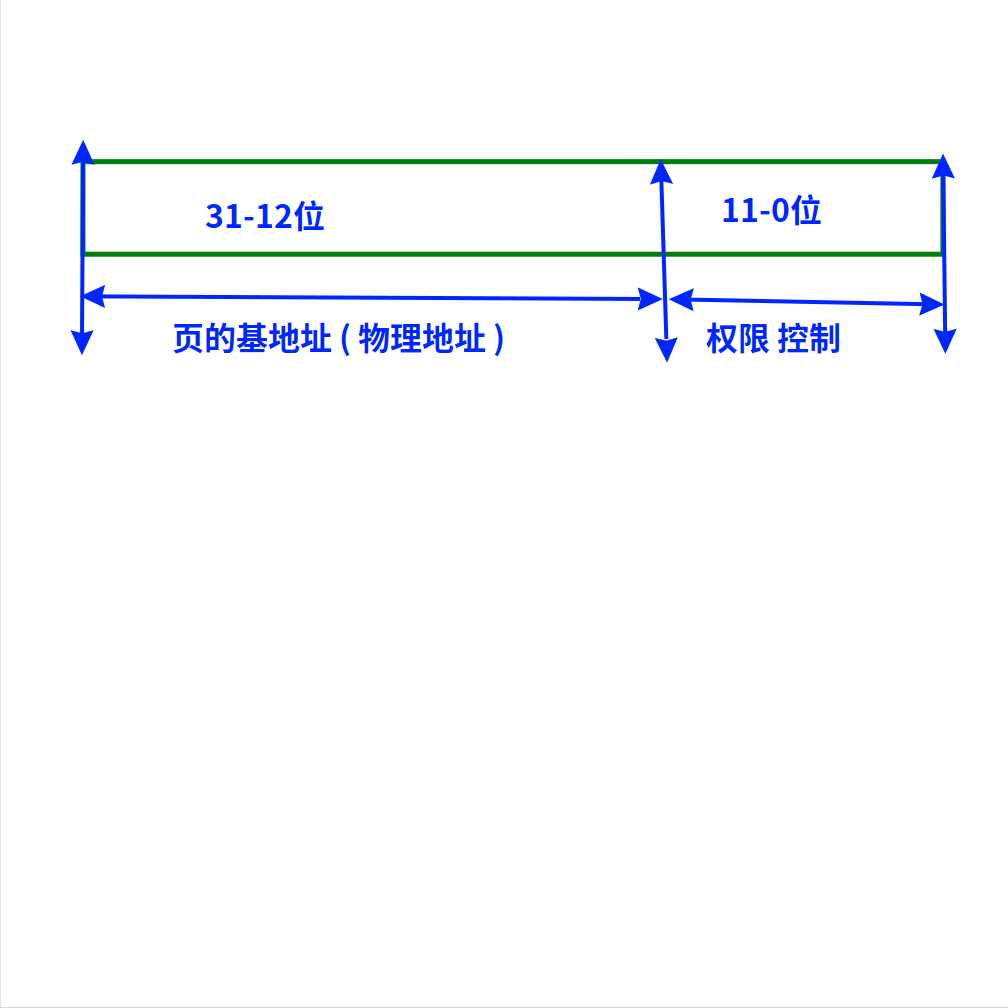
32位的页表项
在开启分页之前,需要先给内存分段。
在32位机上,通常把所有的段都映射到0-4G的虚拟空间。
这时,代码段、数据段、堆栈段的基地址已经没什么用了,CS、DS、SS段寄存器主要用于权限控制,改叫段选择符。
段选择符,是个以8为间隔的等差数列。
0号不用,代码段是0x8,数据段是0x10,堆栈段是0x18。
它们对应的内存地址、内存范围、内存权限,都要写在全局描述符表(GDT)里。
GDT:global descriptor table.
在开启分段之前,需要加载GDT表到CPU的特殊寄存器,用的指令是LGDT:这也是个特殊指令,只能在内核里用,而且一般只用在初始化时。
这里还需要加载中断向量表 (IDT):interrupt descriptor table.
中断向量表,是用来处理硬件中断的函数指针,也就是所谓的中断服务例程 (irq)。
在开启分段之前,先给它留出内存位置来,以后才会设置它。
加载完GDT和IDT之后,打开A20地址线,CPU就可以访问1M以上的内存地址了。
然后,开启内存的分段模式。
接下来就是Linux引导程序里著名的那条汇编:
ljmp $8,$0
跳转到代码段的第一条代码第一条代码的偏移量是0,代码段的选择符是8。
再接着,就是设置内核页表,然后开启分页机制。
内核页表至少分2级,64位机上的分级比较多,32位机上只能分2级:页目录、页表。
不过每一级的表项都差不多,都是页的基地址+访问权限。
页表里填写的内存地址,都是物理内存的地址。
在进程访问内存的时候,虚拟地址会被内存管理单元(MMU)转化到物理地址,然后送到CPU的地址总线,然后内存数据从数据总线传到CPU的寄存器。
32位机的虚拟地址到物理地址的计算:最高10位确定页目录的位置,中间10位确定页表的位置,最后12位确定偏移量:
paddr = dir [ vaddr >> 22 ] [ (vaddr >> 12) & 0x3ff ] [ vaddr & 0x3ff ].
(64位机的,我没仔细看过intel的手册,有兴趣的可以自己去看)
分页机制下,一行mov rax, (rdx),硬件和操作系统实际上要做很多事的。
在把页表设置好之后,要把页表的基地址加载到CPU的cr3寄存器:页目录基地址寄存器。
然后,就可以跳转到内核C代码的main()函数了。
因为页表已经设置好了,接下来就可以用C语言写了。
上面说的那些,都是汇编代码的内容
6.内核子系统的初始化
进入C语言的main()函数之后,首先是各种内核子系统的初始化:
1) 缺页中断
当进程访问的虚拟地址对应的物理内存页不存在时,由缺页中断进行处理:合理的缺页给它申请新的物理内存页,不合理的缺页给进程一个段错误。
段错误,会导致进程被操作系统的信号机制杀死。
2) 时钟中断
它是操作系统的调度节拍,由一个硬件时钟每1毫秒发送一次。
3) 系统调用
它是用户程序与操作系统的唯一接口。
write()系统调用就是其中之一,它是printf()函数的底层机制。
4) 控制台
内核打印日志的必需模块,它是内核printk()函数的底层机制,也是用户的shell控制台的底层机制。
键盘驱动程序,VGA驱动程序,一般都放在控制台模块里,用于给系统提供最初级的输入输出支持。
5) 进程管理
这是内核的核心模块,折腾了这么多,就是为了让用户的多个进程可以切换
fork()系统调用,exit()系统调用、wait()系统调用,getpid()系统调用,kill()系统调用,都属于这个模块。
6) 内存管理
也是内核的核心模块,整个操作系统就是围绕着内存管理来的。
kmalloc()函数、kfree()函数、get_free_pages()函数、brk()系统调用,都属于这个模块。
brk()系统调用,是设置用户进程的数据段的终止位置,也就是堆内存的终止位置,是malloc()和free()函数的底层机制。
get_free_pages()函数,内核分配物理内存页的函数。
7) 文件系统
unix系的操作系统上,一切都是文件。
这是传承自C语言之父丹尼斯-里奇的设计理念。
open()、close()、read()、write(),这4个系统调用,都属于文件系统。
execve()系统调用,它虽然属于进程管理,但是因为要加载可执行文件,所以严重依赖文件系统。
8) 网络子系统
TCP/IP协议栈+ Net Filter +网卡驱动程序,这3个是网络子系统的内容。
Linux网络子系统的作者是Alan Cox,阿兰-寇克斯。
整个互联网的基础,都在这个子系统里。
TCP、UDP、IP、ICMP、ARP、DNS,etc,这些网络协议全在这个模块里。
9) 各种设备的驱动程序
鼠标、显卡、USB、硬盘,等等,大多数设备的驱动程序,都属于这部分。
大致分为:块设备、字符设备、网络设备。
硬盘是块设备,它的最小访问单元是扇区,每个扇区512字节。
字符设备,是可以按字节访问的,显示器是典型的字符设备。
网络设备,网卡是典型的网络设备,它也属于网络子系统。
7.0号进程的创建
0号进程,在操作系统里叫idle进程,是CPU空闲时运行的进程。
当各种内核子系统初始化完成之后,操作系统就要创建0号进程,做为以后所有进程的模板。
进程的数据结构里,主要有这么几项:
1) EIP,用户态的代码地址,
2) ESP,用户态的栈地址,
3) ESP0,内核态的栈地址,
4) cr3,页表的物理地址,
5) pid,进程号,
6) ppid,父进程号,
7) brk,用户代码的数据段末尾,
8) 用户态的代码段、数据段、堆栈段的位置,
可以用于检测段错误,防范缓冲区溢出攻击。
9) 信号图,
处理进程的信号机制。
10) 进程的段选择符,
内核和用户进程的段选择符是不一样的,因为内核是ring0最高权限,用户进程是ring3最低权限。
把进程的这些数据加载到CPU的任务寄存器,然后降低权限到ring3,执行中断返回,就到了了用户态了:
这时的进程是idle进程,它的代码只有1行:
pause();
即,运行pause()系统调用:在有其他进程的情况下,它会调度其他进程运行;如果没有其他进程,它会运行功耗最低的那条pause指令,以降低CPU的功耗。
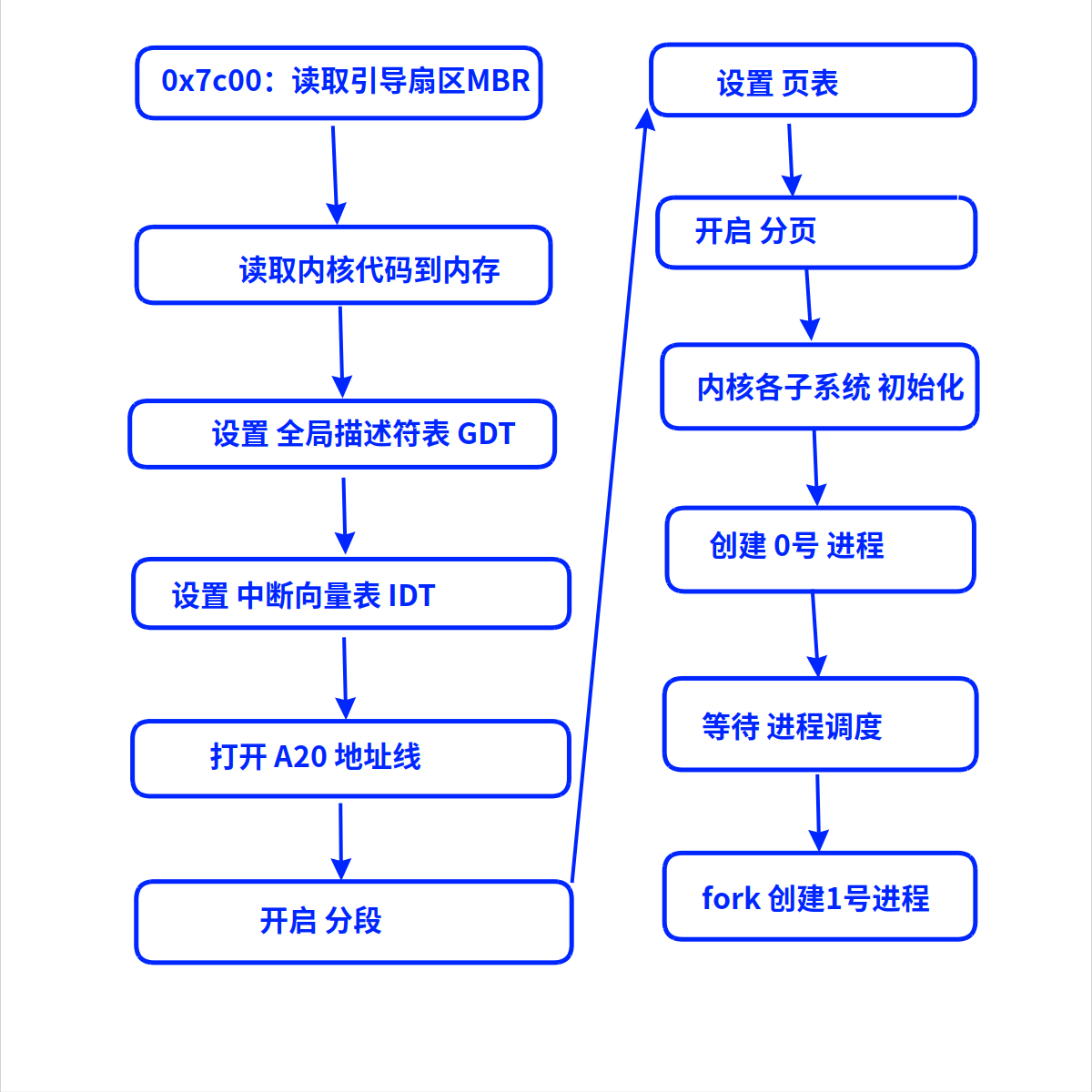
OS内核的总流程
最后,就是fork唯一的1号init进程,然后给用户启动shell或者图形界面了。
不管是shell还是图形界面,它们本质上都是用户的进程。




















